


Glossario IDP: i termini chiave dell’Intelligent Document Processing
Qui di seguito troverete un glossario che elenca e definisce i termini essenziali per comprendere e sfruttare al meglio l'automazione intelligente dei documenti.
Glossario IDP: elenco termini essenziali dell’Intelligent Document Processing
Il mondo dell’Intelligent Document Processing utilizza termini tecnici legati a OCR, intelligenza artificiale, estrazione dati e automazione documentale.
Negli ultimi anni a questo vocabolario si sono aggiunti anche concetti legati ai modelli linguistici e multimodali, come LLM, SLM, VLM, SVLM, MLLM e RAG documentale.
In questo glossario trovi le definizioni essenziali per comprendere come funziona una piattaforma IDP e quali concetti sono più importanti nei processi di digitalizzazione dei documenti aziendali.
Concetti base dell’IDP
Intelligent Document Processing
L’Intelligent Document Processing, spesso abbreviato in IDP, è un insieme di tecnologie che consente di acquisire, classificare, leggere ed estrarre dati da documenti digitali o cartacei.
A differenza del semplice OCR, una soluzione IDP non si limita a trasformare un’immagine in testo, ma interpreta il contenuto del documento e restituisce dati strutturati, validabili e integrabili nei sistemi aziendali.
L’IDP viene utilizzato per automatizzare la gestione di fatture, bollette, documenti d’identità, passaporti, buste paga, contratti, moduli e altri documenti ricorrenti.
Optical Character Recognition
L’Optical Character Recognition, o OCR, è una tecnologia che riconosce lettere, numeri e simboli presenti in un documento e li converte in testo digitale leggibile da una macchina.
L’OCR è una componente fondamentale dell’automazione documentale, ma da solo non è sufficiente per comprendere il significato dei dati. Per questo, nelle piattaforme IDP moderne, viene combinato con intelligenza artificiale, machine learning, NLP e modelli di estrazione avanzata.
Zonal OCR
Lo Zonal OCR è una tecnica OCR che estrae testo solo da aree specifiche e predefinite del documento.
Invece di leggere l’intera pagina, il sistema si concentra su zone precise, come il campo “totale”, “data”, “numero documento” o “codice fiscale”.
Questa tecnica può aumentare la precisione su documenti con layout fisso, ma è meno efficace su documenti semi-strutturati o variabili, dove le informazioni possono cambiare posizione.
Template matching
Il template matching è una tecnica che confronta un documento con un modello predefinito per individuare campi e informazioni in posizioni note.
È efficace su documenti strutturati o molto standardizzati, come moduli sempre uguali, ma diventa meno adatto quando i layout cambiano spesso.
Nelle piattaforme IDP moderne, il template matching può essere affiancato o superato da modelli AI più flessibili, capaci di comprendere il contenuto anche quando la posizione dei dati varia.
Intelligent Character Recognition
L’Intelligent Character Recognition, o ICR, è un’evoluzione dell’OCR specializzata nel riconoscimento del testo scritto a mano.
È più complesso dell’OCR tradizionale perché deve gestire la variabilità della calligrafia. Viene usato, ad esempio, su moduli compilati manualmente, annotazioni, documenti cartacei e firme estese.
Document AI
La Document AI indica il campo più ampio che applica l’intelligenza artificiale alla comprensione, all’elaborazione e alla generazione di contenuti a partire dai documenti.
Include tecnologie come OCR, classificazione automatica, estrazione dati, analisi semantica, validazione intelligente e modelli multimodali.
Mentre l’IDP è la soluzione applicativa che trasforma i documenti in dati pronti per il business, la Document AI è la disciplina tecnologica che rende possibile questo processo.
Maggiori informazioni Document AI
Automazione documentale
L’automazione documentale è il processo che consente di ridurre o eliminare attività manuali legate alla gestione dei documenti.
Può includere acquisizione, lettura, classificazione, estrazione, verifica e invio dei dati verso software gestionali, ERP, CRM o database aziendali.
L’IDP rappresenta una forma avanzata di automazione documentale perché utilizza intelligenza artificiale per gestire anche documenti variabili e complessi.
Maggiori informazioni Automazione Documentale
Tipologie di documenti
Documento strutturato
Un documento strutturato segue uno schema fisso e prevedibile. Layout, campi, posizione delle informazioni e formato sono generalmente uguali tra le diverse copie dello stesso documento.
Un esempio di documento strutturato è la carta d’identità, dove nome, cognome, data di nascita, numero documento e altri dati si trovano in aree definite.
Documento semi-strutturato
Un documento semi-strutturato contiene informazioni ricorrenti, ma non sempre nella stessa posizione o con lo stesso formato.
È il caso tipico delle fatture, delle bollette o delle buste paga. In questi documenti, campi come data, importo, codice fiscale, partita IVA o numero documento sono spesso presenti, ma possono cambiare posizione in base al fornitore, al modello o al layout.
Documento non strutturato
Un documento non strutturato non segue uno schema fisso e può contenere informazioni distribuite liberamente nel testo.
Contratti, lettere, relazioni, comunicazioni formali e documenti narrativi sono esempi di documenti non strutturati.
Per elaborarli correttamente, una soluzione IDP deve comprendere il contesto e il significato delle informazioni, non solo la loro posizione nel documento.
Maggiori informazioni Documenti strutturati, semi-strutturati e non strutturati
PDF nativo e PDF scansionato
Un PDF nativo, o born-digital, è generato direttamente da un software e contiene un testo già selezionabile e ricercabile.
Un PDF scansionato, invece, è di fatto un’immagine del documento e richiede l’OCR per estrarne il testo.
La distinzione è importante perché incide sull’accuratezza e sul tipo di elaborazione necessaria: un documento scansionato di bassa qualità è più soggetto a errori di lettura rispetto a un PDF nativo.
Le fasi dell’Intelligent Document Processing
Data capture
Il data capture è il processo di acquisizione dei dati da documenti, immagini, PDF, email o altri canali.
Nell’IDP rappresenta una delle prime fasi del flusso di lavoro, perché consente di trasformare un documento in una fonte di dati elaborabile.
Pre-processing
Il pre-processing è la fase di preparazione del documento che precede l’estrazione.
Può includere operazioni come il raddrizzamento dell’immagine, la rimozione del rumore, il miglioramento del contrasto o la separazione delle pagine.
Un buon pre-processing migliora la qualità dell’OCR e dell’estrazione successiva, soprattutto sui documenti scansionati o di scarsa qualità.
Document parsing
Il document parsing è il processo che analizza la struttura di un documento per separare, riconoscere e organizzare le informazioni contenute al suo interno.
Può riguardare paragrafi, tabelle, intestazioni, righe, campi e sezioni del documento.
Il parsing è una fase tecnica all’interno del flusso IDP, non un suo sinonimo: serve a trasformare un documento complesso in dati ordinati su cui operano poi classificazione ed estrazione.
Classificazione dei documenti
La classificazione dei documenti consiste nell’assegnare automaticamente una o più categorie a un documento.
Per esempio, una piattaforma IDP può riconoscere se un file è una fattura, una bolletta, un documento d’identità, una busta paga o un contratto.
Questo passaggio è importante perché consente di applicare il modello di estrazione più adatto a ogni tipologia documentale.
Document indexing
Il document indexing è il processo di assegnazione di metadati, etichette e chiavi di ricerca a un documento.
Serve a rendere i documenti più facili da archiviare, trovare e recuperare all’interno di un sistema documentale.
Nel contesto IDP, l’indicizzazione può basarsi su dati estratti automaticamente, come tipologia di documento, data, nome cliente, numero pratica, codice fiscale, fornitore o stato di lavorazione.
Estrazione di informazioni
L’estrazione di informazioni è il processo che consente di individuare e recuperare dati specifici da un documento.
Può riguardare dati anagrafici, importi, date, codici fiscali, partite IVA, numeri documento, indirizzi o altre informazioni rilevanti.
Nell’IDP, l’estrazione dati non si basa solo sulla posizione del testo, ma anche sul significato dei campi.
Validazione dei dati
La validazione dei dati è il controllo che verifica se le informazioni estratte sono corrette, complete e coerenti.
Può essere automatica, manuale o mista.
Per esempio, un sistema può controllare se un codice fiscale ha una struttura valida, se una data è coerente o se il totale di una fattura corrisponde alla somma degli importi presenti nel documento.
Post-processing
Il post-processing è la fase successiva all’estrazione dei dati.
Serve a normalizzare, correggere, validare o arricchire le informazioni prima che vengano inviate ai sistemi aziendali.
Per esempio, una data può essere convertita in un formato standard oppure un importo può essere verificato rispetto ad altri valori presenti nel documento.
Human-in-the-loop
Human-in-the-loop, spesso abbreviato in HITL, indica il processo in cui un operatore umano interviene per verificare, correggere o confermare i risultati prodotti da un modello di intelligenza artificiale.
Questo approccio combina la velocità dell’automazione con il controllo umano, aumentando l’affidabilità dei dati nei casi più complessi o ambigui.
Dati estratti e struttura dell’output
Coppia chiave-valore
Una coppia chiave-valore è una struttura dati composta da un’etichetta, la chiave, e dal valore corrispondente.
Esempio:
Totale fattura → 1.220,00 €
È uno dei formati principali con cui l’IDP restituisce i dati estratti, perché rende ogni informazione immediatamente identificabile e integrabile nei sistemi aziendali.
Line-item
Un line-item è una singola riga di una tabella o di un elenco all’interno di un documento, come le righe di una fattura o di uno scontrino.
Estrarre i line-item richiede di riconoscere la struttura tabellare e l’associazione corretta tra colonne e valori, come descrizione, quantità, prezzo e totale.
Estrazione di tabelle
L’estrazione di tabelle è il processo che individua e ricostruisce le tabelle presenti in un documento, mantenendo la relazione tra righe, colonne e celle.
È una delle attività più complesse dell’IDP, perché le tabelle variano molto per layout e possono estendersi su più pagine.
Riconoscimento firme
Il riconoscimento firme è la capacità di individuare la presenza, la posizione ed eventualmente lo stato di una firma all’interno di un documento.
È utile, ad esempio, per verificare che un contratto o un modulo sia stato firmato prima di proseguire nel flusso.
Entità
Un’entità è un’informazione significativa identificata all’interno di un testo: nomi di persone, aziende, date, importi, indirizzi o codici.
Il Named Entity Recognition, o NER, è la tecnica che individua e classifica automaticamente queste entità, ed è uno dei mattoni dell’estrazione dati nei documenti.
Schema di estrazione
Lo schema di estrazione è la definizione dei campi che il sistema deve recuperare da una determinata tipologia di documento, con il relativo formato atteso.
Funziona come un modello dati di riferimento: stabilisce, ad esempio, che da una fattura vanno estratti numero, data, fornitore, imponibile, IVA e totale.
Bounding box
Un bounding box è il riquadro di coordinate che individua la posizione esatta di un elemento, come un campo, una parola o una tabella, all’interno dell’immagine del documento.
È alla base del visual grounding, perché permette di collegare ogni dato estratto al punto preciso da cui proviene.
Tecnologie e modelli di AI
Algoritmi
Un algoritmo è una sequenza ordinata di istruzioni che consente a un sistema informatico di svolgere un compito o risolvere un problema.
Nel contesto dell’Intelligent Document Processing, gli algoritmi vengono utilizzati per classificare documenti, riconoscere pattern, estrarre dati, confrontare informazioni e automatizzare decisioni all’interno del workflow documentale.
Machine Learning
Il Machine Learning è una branca dell’intelligenza artificiale che consente ai sistemi di apprendere da esempi e dati.
Nell’IDP viene utilizzato per riconoscere tipologie di documenti, individuare campi rilevanti e migliorare progressivamente la precisione dell’estrazione.
Apprendimento supervisionato
L’apprendimento supervisionato è una tecnica di Machine Learning in cui un modello viene addestrato usando dati già etichettati.
Nel contesto IDP, può essere utilizzato per insegnare al sistema a riconoscere specifiche tipologie di documenti o campi, come fatture, codici fiscali, importi, date o numeri documento.
Il modello impara confrontando gli esempi di input con l’output corretto atteso e migliora progressivamente la propria capacità di previsione.
Apprendimento non supervisionato
L’apprendimento non supervisionato è una tecnica di Machine Learning in cui il modello analizza dati non etichettati per individuare schemi, somiglianze o gruppi ricorrenti.
Nell’IDP può essere utile per riconoscere automaticamente documenti simili, individuare cluster di layout, rilevare anomalie o organizzare grandi archivi documentali senza dover definire manualmente ogni categoria in anticipo.
Apprendimento per rinforzo
L’apprendimento per rinforzo è un metodo di Machine Learning in cui un modello impara attraverso feedback positivi o negativi ricevuti dall’ambiente.
Nel contesto documentale è meno comune rispetto all’apprendimento supervisionato, ma può essere applicato in scenari avanzati in cui il sistema deve ottimizzare progressivamente le proprie decisioni, ad esempio scegliendo il percorso migliore di validazione o migliorando il workflow in base agli esiti precedenti.
Deep Learning
Il Deep Learning è una tecnica avanzata di Machine Learning basata su reti neurali.
È particolarmente utile nell’elaborazione di documenti complessi, immagini, layout variabili e testi non sempre perfettamente leggibili.
Nell’IDP viene spesso usato per migliorare OCR, classificazione, comprensione del layout e riconoscimento dei campi.
Natural Language Processing
Il Natural Language Processing, o NLP, è la tecnologia che consente ai software di analizzare e comprendere il linguaggio umano.
Nell’IDP viene utilizzato per interpretare testi, identificare entità, comprendere relazioni tra parole e riconoscere il significato delle informazioni presenti nei documenti.
Computer Vision
La Computer Vision è una tecnologia che consente ai sistemi di analizzare immagini e contenuti visivi.
Nell’IDP viene usata per riconoscere layout, tabelle, firme, timbri, campi, sezioni e altri elementi grafici presenti nei documenti.
Large Language Model
Un Large Language Model, o LLM, è un modello di intelligenza artificiale addestrato su grandi quantità di testo per comprendere e generare linguaggio naturale.
Nell’IDP gli LLM permettono di interpretare il significato dei documenti, non solo la posizione del testo.
Se usati in modo generico, però, gli LLM possono risultare costosi, lenti e soggetti ad allucinazioni. Per questo nei contesti documentali vengono spesso preferiti modelli più piccoli e specializzati.
Small Language Model
Uno Small Language Model, o SLM, è un modello linguistico di dimensioni ridotte, specializzato su compiti specifici.
Rispetto a un LLM generalista offre maggiore velocità, costi inferiori e maggiore controllo, mantenendo un’accuratezza elevata sul dominio per cui è ottimizzato.
Nell’IDP può essere usato, ad esempio, per una determinata categoria di documenti, come fatture, bollette o buste paga.
Vision-Language Model
Un Vision-Language Model, o VLM, è un modello che elabora insieme testo e immagine, “vedendo” il documento invece di leggerne solo il testo trascritto.
Questo gli consente di interpretare layout, tabelle, posizione dei campi ed elementi grafici senza dipendere esclusivamente dall’OCR.
I modelli multimodali sono alla base delle soluzioni IDP più recenti, perché trattano il documento nella sua interezza visiva e testuale.
Small Vision-Language Model
Uno Small Vision-Language Model, o SVLM, è una versione più leggera e specializzata di un modello vision-language.
Combina comprensione visiva e linguistica, ma con un’architettura più efficiente rispetto ai grandi modelli multimodali.
Nel contesto IDP, gli SVLM sono utili quando bisogna analizzare grandi volumi di documenti mantenendo tempi di risposta rapidi e costi di elaborazione contenuti.
Possono supportare attività come riconoscimento del layout, individuazione dei campi, lettura di tabelle, controllo di documenti scansionati e verifica visuale delle informazioni estratte.
Rispetto a un VLM generalista, uno SVLM può essere ottimizzato per domini specifici, come fatture, bollette, documenti d’identità, passaporti o buste paga, migliorando il rapporto tra accuratezza, velocità e costo operativo.
Multimodal Large Language Model
Un Multimodal Large Language Model, o MLLM, è un modello di grandi dimensioni capace di elaborare più tipi di input, come testo, immagini e documenti.
Nell’IDP può leggere il contenuto testuale, interpretare la struttura visiva della pagina e ragionare sulle relazioni tra campi, tabelle, firme, timbri e sezioni del documento.
Gli MLLM sono particolarmente utili su documenti complessi o poco standardizzati, ma richiedono controlli rigorosi su costi, tempi di risposta, sicurezza e rischio di allucinazione.
Embeddings documentali
Gli embeddings documentali sono rappresentazioni numeriche del contenuto di un documento, di una frase o di un campo.
Consentono ai sistemi AI di confrontare informazioni in base al significato, non solo alla presenza esatta delle parole.
Nell’IDP possono essere usati per ricerca semantica, classificazione documentale, deduplicazione, confronto tra documenti simili e recupero di informazioni rilevanti all’interno di archivi aziendali.
RAG documentale
La Retrieval-Augmented Generation, o RAG, è un approccio che combina modelli generativi e recupero di informazioni da fonti documentali.
Prima di generare una risposta, il sistema cerca contenuti pertinenti nei documenti disponibili e li usa come contesto.
Nel contesto IDP, la RAG può essere utile per interrogare archivi documentali, rispondere a domande su contratti, manuali o pratiche aziendali e ridurre il rischio che il modello produca risposte non fondate sui documenti originali.
Generative AI
La Generative AI indica i modelli di intelligenza artificiale capaci di generare contenuti nuovi, come testo, dati strutturati o riassunti, a partire da un input.
Nell’IDP può essere usata per estrarre e riorganizzare informazioni in linguaggio naturale, ma richiede controlli adeguati per evitare allucinazioni e garantire l’affidabilità del dato.
Addestramento del modello
L’addestramento del modello è il processo attraverso cui un sistema di intelligenza artificiale impara a riconoscere pattern, campi e informazioni a partire da esempi reali.
Più i dati di addestramento sono rappresentativi e di qualità, maggiore sarà la precisione del modello nei casi reali.
Fine-tuning
Il fine-tuning è la specializzazione di un modello già pre-addestrato su un compito o un dominio specifico, tramite un insieme aggiuntivo di esempi mirati.
Nell’IDP consente di adattare un modello generale a una particolare tipologia di documenti o a un settore, migliorandone l’accuratezza senza doverlo addestrare da zero.
Generalizzazione
La generalizzazione è la capacità di un modello di intelligenza artificiale di funzionare correttamente anche su dati nuovi, diversi da quelli usati durante l’addestramento.
Nell’IDP è una caratteristica importante perché i documenti reali possono variare molto per layout, qualità, formato e contenuto.
Un modello con buona generalizzazione riesce a estrarre dati anche da documenti mai visti prima, mentre un modello troppo legato agli esempi di training rischia di funzionare bene solo su casi molto simili a quelli già conosciuti.
Overfitting
L’overfitting si verifica quando un modello impara troppo bene i dettagli dei dati di addestramento, inclusi rumori, eccezioni o particolarità non generalizzabili.
In questi casi il modello può ottenere buoni risultati sui documenti usati per il training, ma performare male su documenti nuovi.
Nel contesto IDP, l’overfitting può portare a estrazioni poco affidabili quando cambiano layout, fornitori, formati o condizioni di scansione.
Zero-shot e few-shot
Zero-shot e few-shot descrivono la capacità di un modello di svolgere un compito rispettivamente senza alcun esempio o con pochissimi esempi forniti al momento della richiesta.
Nell’IDP sono utili per gestire documenti nuovi o rari, su cui non è disponibile un addestramento dedicato.
Prompt
Il prompt è l’istruzione o l’input che si fornisce a un modello generativo per ottenere il risultato desiderato.
Nell’estrazione documentale, un prompt ben costruito guida il modello a restituire i campi richiesti nel formato corretto.
Token
Il token è l’unità minima di testo che un modello elabora. Può corrispondere a una parola, a una parte di parola o a un simbolo.
Il numero di token influisce sui costi e sui tempi di elaborazione di un modello linguistico.
Qualità, controllo e accuratezza
Confidence score
Il confidence score è un punteggio che indica il livello di sicurezza con cui il sistema ha riconosciuto o estratto un dato.
Un valore alto indica maggiore affidabilità, mentre un valore basso può richiedere una revisione umana.
Per esempio, se il sistema estrae un codice fiscale con un confidence score basso, può inviarlo a un operatore per la verifica.
Accuratezza
L’accuratezza misura quanto i risultati prodotti dal sistema siano corretti rispetto ai dati reali.
Nell’IDP è un indicatore fondamentale per valutare l’efficacia di una soluzione di automazione documentale.
Precision, Recall e F1
Precision, recall e F1 sono metriche usate per valutare la qualità dell’estrazione in modo più preciso dell’accuratezza complessiva.
La precision indica quanti dei dati estratti sono corretti.
Il recall indica quanti dei dati presenti nel documento sono stati effettivamente recuperati.
L’F1 è la media armonica tra precision e recall e offre una misura sintetica e bilanciata.
Tasso di errore
Il tasso di errore indica la percentuale di dati riconosciuti o estratti in modo errato.
Ridurre il tasso di errore è uno degli obiettivi principali di una piattaforma IDP, soprattutto nei processi aziendali in cui la qualità del dato è critica.
Errore umano
L’errore umano è un errore non intenzionale causato da una persona durante un’attività manuale.
Può riguardare inserimento dati, lettura errata di un documento, duplicazione di informazioni o dimenticanze.
L’automazione documentale riduce il rischio di errore umano nei processi ripetitivi e ad alto volume.
Allucinazione
L’allucinazione è il fenomeno per cui un modello generativo produce un’informazione plausibile ma non presente nel documento.
Nell’estrazione documentale è un rischio critico, perché un dato inventato può sembrare corretto pur non avendo riscontro nella fonte.
Tecniche come visual grounding, confidence score e validazione servono a contenere questo rischio, garantendo che ogni dato estratto sia verificabile.
Visual grounding
Il visual grounding, o ancoraggio alla fonte, è la capacità del sistema di collegare ogni dato estratto al punto preciso del documento da cui proviene.
Può avvenire tramite coordinate, riquadri, righe o aree evidenziate nel documento.
Consente di verificare l’origine di ogni informazione e rende l’AI più trasparente, evitando che il sistema si comporti come una scatola nera.
Benchmark
Un benchmark è un insieme standardizzato di documenti e metriche usato per misurare e confrontare le prestazioni di sistemi diversi su uno stesso compito.
Nell’IDP serve a valutare in modo oggettivo l’accuratezza di OCR, classificazione ed estrazione.
Ground truth
La ground truth, o verità di riferimento, è l’insieme dei dati corretti, verificati manualmente, rispetto a cui si misurano i risultati di un sistema.
È indispensabile sia per addestrare i modelli sia per valutarne l’accuratezza in modo affidabile.
Integrazione, business e compliance
Workflow documentale
Un workflow documentale è il flusso operativo che un documento segue all’interno di un’organizzazione.
Può includere ricezione, classificazione, estrazione dati, approvazione, archiviazione e invio verso altri sistemi.
L’IDP consente di automatizzare molte fasi del workflow documentale.
Business Process Management
Il Business Process Management, o BPM, è l’insieme di metodi e strumenti utilizzati per progettare, gestire, monitorare e ottimizzare i processi aziendali.
Nel contesto IDP, il BPM può orchestrare il workflow documentale end-to-end: ricezione del documento, classificazione, estrazione dati, validazione, approvazione e invio ai sistemi aziendali.
L’integrazione tra IDP e BPM consente di trasformare l’automazione documentale in un processo strutturato, misurabile e controllabile.
Straight-through processing
Lo straight-through processing, o STP, indica la percentuale di documenti elaborati end-to-end senza alcun intervento umano.
Spesso viene chiamato anche tasso di automazione.
È uno degli indicatori di valore più importanti di una soluzione IDP, perché misura quanto lavoro manuale viene effettivamente eliminato.
API
Un’API è un’interfaccia che consente a due software di comunicare tra loro.
Nell’IDP, le API permettono di collegare la piattaforma di estrazione documentale a gestionali, ERP, CRM, database o altri sistemi aziendali.
Data mapping
Il data mapping è il processo che definisce la corrispondenza tra i dati estratti da un documento e i campi presenti in un altro sistema.
Per esempio, il campo “Totale fattura” estratto da una fattura può essere collegato al campo “amount_total” di un ERP o gestionale aziendale.
Nel contesto IDP, il data mapping è fondamentale per integrare correttamente le informazioni estratte nei sistemi di destinazione, evitando errori di associazione o perdita di dati.
ERP
Un ERP è un sistema gestionale utilizzato dalle aziende per amministrare processi come contabilità, acquisti, vendite, magazzino, risorse umane e produzione.
Una piattaforma IDP può inviare i dati estratti dai documenti direttamente all’ERP, riducendo il data entry manuale.
RPA
La Robotic Process Automation, o RPA, è una tecnologia che automatizza attività ripetitive eseguite su software e interfacce digitali.
Può essere integrata con l’IDP per automatizzare processi più ampi, come la gestione delle fatture passive o l’inserimento dati nei gestionali.
Data entry manuale
Il data entry manuale è l’inserimento manuale dei dati da parte di un operatore.
È un’attività spesso ripetitiva, lenta e soggetta a errori.
L’IDP consente di ridurre il data entry manuale trasformando automaticamente i documenti in dati strutturati.
Low-code / No-code
Low-code e no-code indicano approcci che permettono di creare applicazioni, workflow o configurazioni software con poca o nessuna programmazione tradizionale.
Le piattaforme low-code richiedono competenze tecniche minime, mentre quelle no-code sono pensate anche per utenti business non sviluppatori.
Nel contesto IDP, strumenti low-code e no-code possono permettere agli utenti di configurare modelli di estrazione, regole di validazione, workflow approvativi e integrazioni senza dover scrivere codice complesso.
Cloud e on-premise
Cloud e on-premise indicano due modalità di erogazione del software.
Nel modello cloud, la piattaforma è ospitata su server gestiti dal fornitore e accessibile via internet.
Nel modello on-premise, invece, è installata sull’infrastruttura interna del cliente.
La scelta incide su sicurezza, manutenzione, aggiornamenti e controllo dei dati, e va valutata in base ai requisiti del settore e alle normative applicabili.
Sovranità del dato
La sovranità del dato, o data sovereignty, è il principio per cui i dati restano soggetti alla legislazione e all’infrastruttura di una giurisdizione specifica.
Per esempio, un’azienda europea può richiedere che i dati vengano archiviati su server europei in conformità al GDPR.
È un requisito centrale nei settori regolamentati e nel trattamento di documenti contenenti dati personali.
GDPR
Il GDPR, General Data Protection Regulation, è il regolamento europeo sulla protezione dei dati personali.
Nell’IDP è rilevante perché i documenti elaborati contengono spesso dati personali e sensibili, il cui trattamento deve rispettare requisiti precisi di sicurezza, conservazione e trasparenza.
Audit trail
L’audit trail, o tracciabilità, è la registrazione cronologica di tutte le operazioni svolte su un documento o su un dato.
Permette di sapere chi ha fatto cosa, quando e con quale esito.
Garantisce la tracciabilità del processo ed è importante per controlli interni, conformità normativa e gestione delle responsabilità.
Articoli correlati

Oltre la Demo: le complessità nascoste nell’addestrare e validare VLMs per la Document AI
Addestrare un VLM per la Document AI può sembrare semplice in demo, ma portarlo in produzione richiede una pipeline robusta: dataset multimodali, fine-tuning controllato e validazione affidabile degli output.
Leggilo ora
Make or Buy nell’IDP: come scegliere l’automazione documentale giusta
Sviluppare o acquistare una piattaforma IDP? Una guida pratica per valutare costi, tempi, scalabilità e rischi nella scelta della migliore soluzione di automazione documentale.
Leggilo ora
OCR vs IDP: differenze e quale tecnologia scegliere
OCR e IDP sono due tecnologie chiave per l’automazione documentale: l’OCR permette di leggere il testo da immagini e PDF, mentre l’IDP comprende il contenuto dei documenti e lo trasforma in dati strutturati pronti per i processi aziendali.
Leggilo ora
Cos'è la Document AI? Evoluzione negli anni e task principali
La Document AI rappresenta l’evoluzione delle tecnologie per comprendere, classificare, estrarre e generare dati dai documenti. L’articolo analizza il passaggio dai sistemi rule-based ai modelli multimodali e il valore delle piattaforme IDP
Leggilo ora
Cos'è l'intelligenza artificiale e perché è importante per le aziende
L’intelligenza artificiale aiuta le imprese ad automatizzare attività, analizzare dati, gestire documenti e rendere più efficienti i processi. In questo articolo vediamo cos’è l’AI, come funziona e dove può generare valore reale in azienda.
Leggilo ora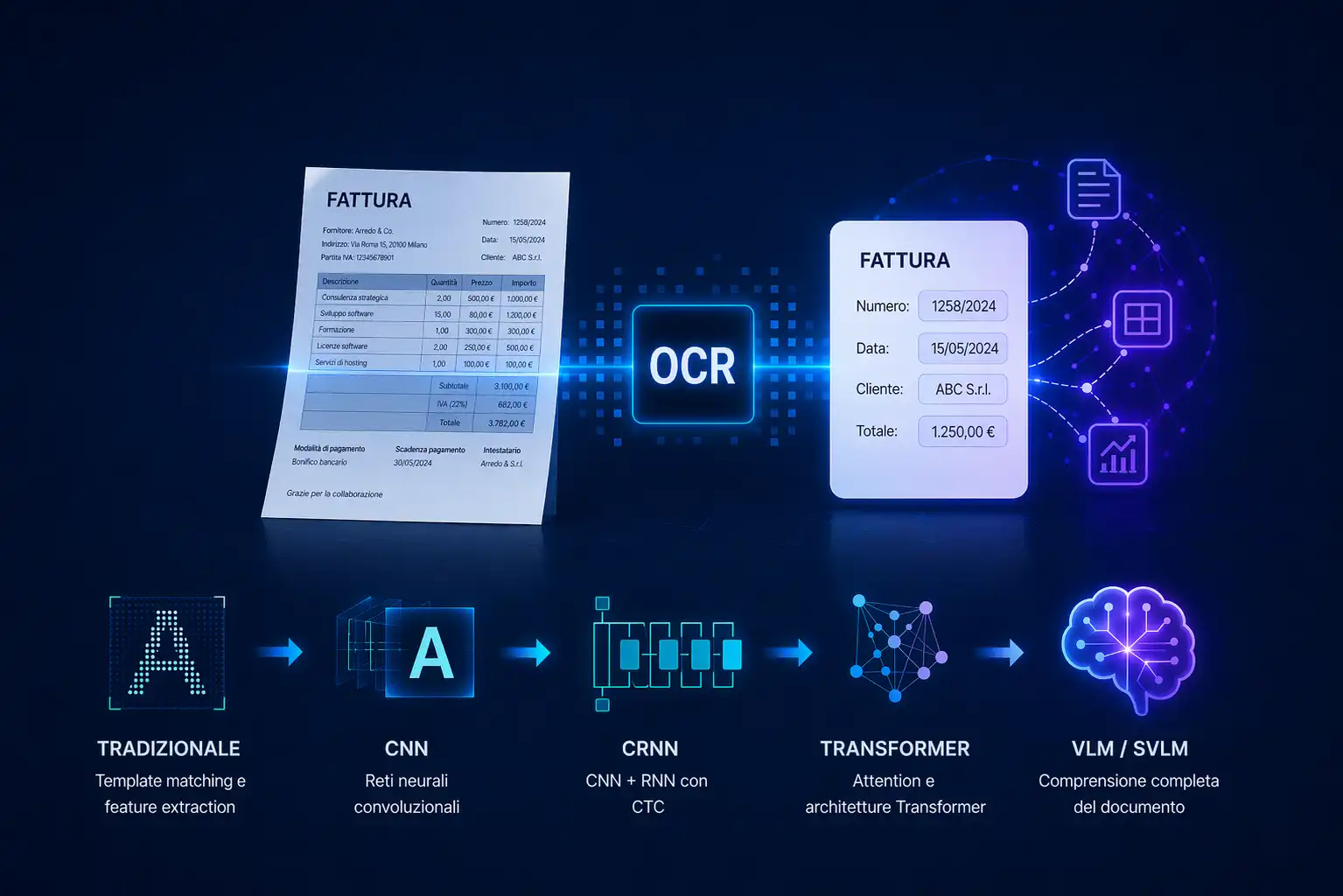
Cos’è l’OCR e come si è evoluto: dalle tecniche tradizionali ai Vision Language Model
L’OCR converte testi da immagini e PDF in contenuti digitali, ma oggi è solo il primo passo. Con VLM e IDP, i sistemi evoluti non si limitano a leggere: comprendono i documenti, strutturano i dati e abilitano l’automazione.
Leggilo ora

.svg)
.svg)
